I used to spend several hours a day combing through feeds, newsletters, and portals concerning topics I found interesting. At first, I merely noted them in memory. Then, as I became interested in being able to refer back to particular developments, I started a simple text file, divided into basic topics, such as "Security", "Programming Languages", etc. After a short time, this became unwieldy and ineffectual.
My next approach was to create an extensible folder structure, finely-grained by topic, containing document files which included the links to stories, tutorials, and other sources of information pertinent to the topic of their directory. I also found it easier to add personal notes and commentary on the information in this way. This method was much more effective, but still very limited.
As time progressed and my collection of information grew, I realized that the structure I had created was limited in two critical respects: 1) adding or editing information was overly time-consuming, as I had to find the appropriate document in the appropriate folder structure, then open, edit, and save it, 2) searching the structure was limited to the search functionality built into Windows, and later to Google Desktop search. It became clear at that stage that the design of my record system needed to be centered around 3 basic principles:
- Ease of entering new information
- Ease of searching for information
- Ease of altering topical structure
Around the time when I began to grow dissatisfied with the folder/document system, I discovered
Treepad. This is a wonderful program, with many potential uses. It allows one to form a structure of "trees" and "leaves" within a single file. Each of the leaves allow for insertion of text and images, and the entire structure can be altered, linked, and seached with ease.
Using Treepad was much more effective, and I would have been satisfied with it, had I not found
Freemind. This allowed for all the features of Treepad, except that I was not limited to an Explorer-style visual interface, but rather a
topic map which could be unfolded as desired. I found it much easier to find information, track developments, and understand topics through this display method than any structure I had used previously.
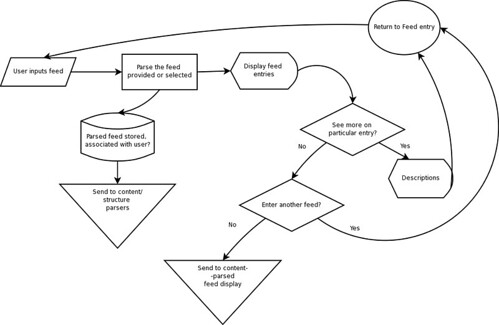
I ran into one final difficulty: as my topics of interest and my databank grew, I found that the time required to search through various feeds and portals, pick out interesting information, and record them in my topic structure was simply too great. Thus emerged the need for a system which I now set out to create. This system (for which I lack an effective name currently) will perform the following basic functions:
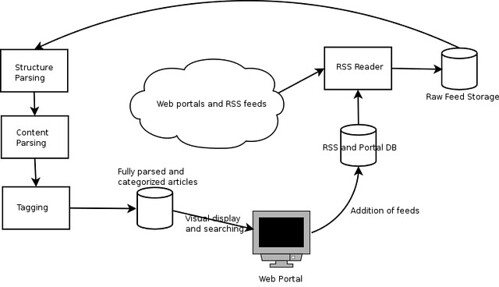
- Record an initial list of syndicated feeds and URLs of portals of interest, and allow for new feeds and sites to be imported
- Read each of the feeds or portals as appropriate and parse the information they contain
- Tag each piece of content based on an extensible topical structure
- Record content and applicable metadata in a database
- Provide an interface for the content to be searched based on a variety of criteria
The system may also be extended to include the following much more advanced features:
- Web spiders to find new feeds and sites which should be of interest based on the current topical structure and areas for which information is lacking and determined to be desired
- Visual interface for graphical display of topical structure and content relations
I hope to write this system mainly in Python, as it seems suit the task well in its simplicity and ability. This blog will serve as a record of the steps in its development, from things I learn about Python, to semantics, and probably much more.

{kind=link}
{kind=link}
{kind=link}