Feedorific design, part 1: Feedreader
Here are my thoughts on the design of Feedorific, Django-version:
The various apps will be:
The various apps will be:
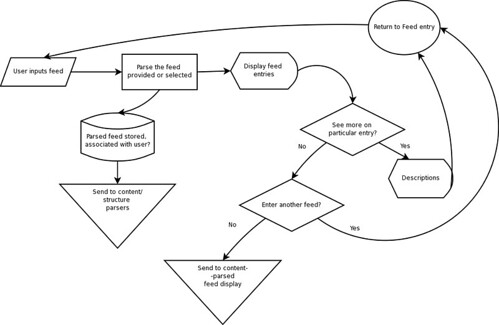
- Feedreader -
Accepts and stores feeds from users, gets the xml, parses out and displays entries and descriptions. Feeds entered will also be stored to DB.
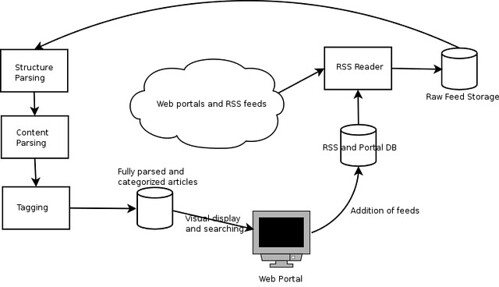
- Structureparser -
Parses stored feeds for their structure.
- Contentparser -
Parses stored feeds for their content.
- Organization -
Very unsure about this last section's design. It will display the fully-parsed feeds, allow searching, tagging, etc. This may also be integrated with a visually-organized display of feed articles by content.

{kind=link}
{kind=link}